

一次提问,跨系统找答案
打通文档、音视频、图像和业务数据,让分散在不同系统里的知识可以被统一检索与调用。
企业每天都在沉淀制度、文档、流程和经验,但真正创造价值的,不是知识本身,而是知识能够在业务中被理解、被调用、被执行。KnowV 要做的,是让企业知识不只被检索和引用,而能进入业务系统、支撑智能体执行,持续沉淀为可复用的企业能力。
企业海量多模态数据与经验长期分散、难以复用。KnowV 统一归集并打通全域知识,
依托智能推理嵌入业务流程,让沉睡的资产落地创造价值。
打通文档、音视频、图像和业务数据,让分散在不同系统里的知识可以被统一检索与调用。
跨模态关联文本、图像、视频、项目和人员,让一次查询呈现完整业务脉络。
面对复杂业务问题,提供多源交叉验证的分析结论,而非简单关键词匹配。
自动生成复盘报告、解答制度疑问、整理过程材料,让知识直接转化为业务生产力。








企业知识网络
传统知识库仅能满足资料查找,KnowV 主动关联文档、视频、人员与业务系统,
让企业知识从孤立的“资料集合”升级为自带上下文的“动态知识网络”。
KnowV 统一接入文本、音视频及底层业务数据,并在同一知识体系中深度理解关联。
不仅能跨模态检索,更提供安全可控的云端运行环境,让智能体持续调用企业知识、自动执行复杂任务。
支持 PDF、Word、Excel、PPT 等办公资料统一管理,并可与图像、视频和业务数据自动关联。
识别图像内容、对象、场景和文字信息,让截图、设计稿和扫描件变得可检索。
理解事件过程、关键行为、时间线和业务场景,把视频沉淀为可复用的知识资产。
关联组织、项目、流程和业务系统数据,让结构化数据与非结构化知识打通。
一次检索,同时获取文档、图像、视频和业务数据中的相关知识,无需分别查找多个系统。
提供安全可控的云端工作空间,支持智能体持续调用企业知识、执行复杂任务并全程留痕。
深层知识推理
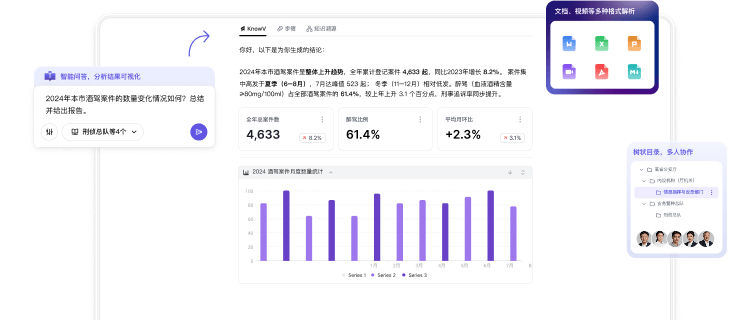
遇到复杂业务难题,企业要的不只是零散资料,而是有据可依的可靠结论。KnowV依托企业自有知识库做多源交叉研判,帮团队提质增效、科学决策。
企业全场景视频蕴含海量细节却难以调取。KnowV深度解析多模态视频,一键打通工单、制度与业务流程,让沉睡的视频转化为可检索、可关联、可复用的核心知识资产。
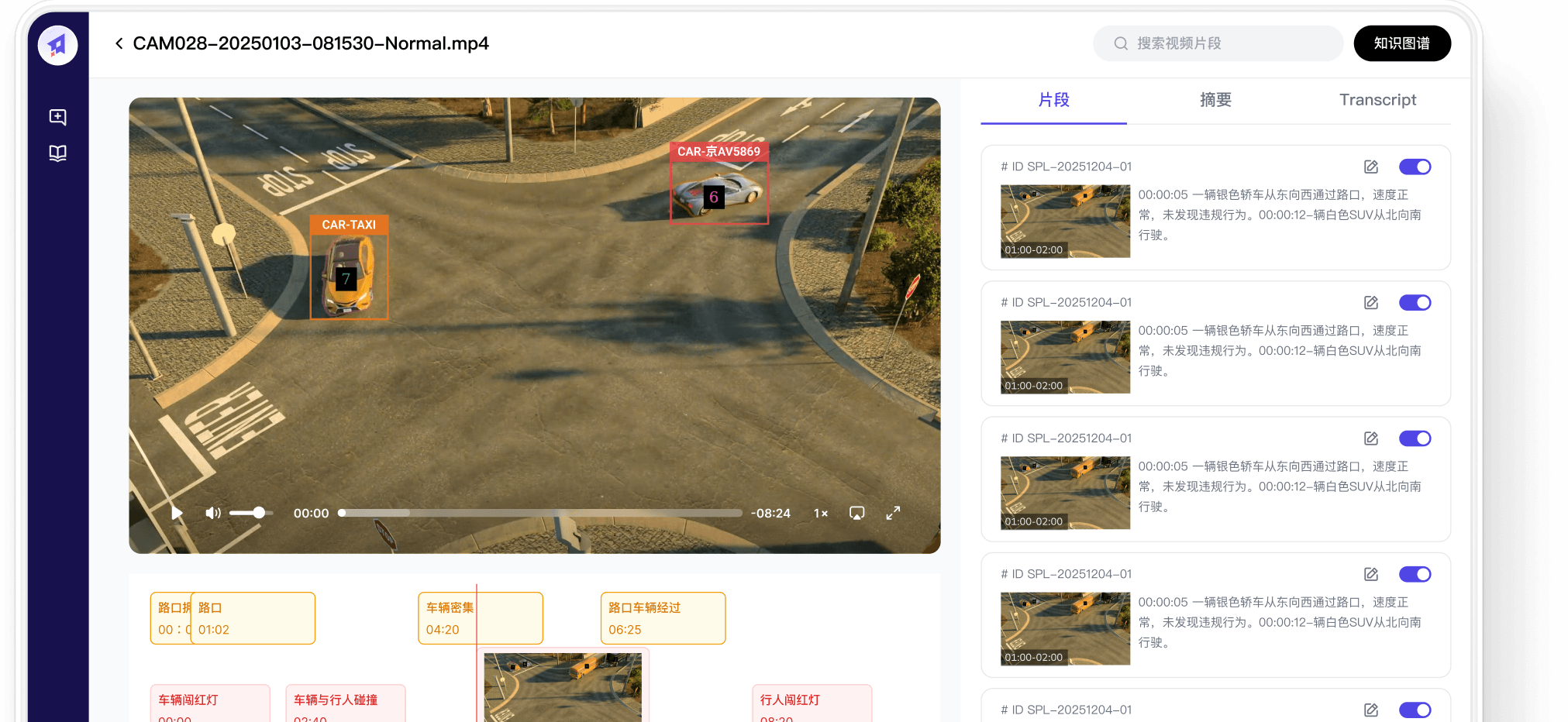
用自然语言从海量视频中精准检索业务片段
自动生成视频摘要,快速提炼关键要点,无需看完整视频。
识别关键事件、行为和时间线
支持将视频事件与制度文档、维修工单、业务流程自动关联
将视频知识沉淀为可复用的企业知识,供培训、复盘、审计使用。
从清晰的业务场景开始,KnowV 将企业知识转化为可分析、可生成、可追溯的业务结果。
员工提问时自动引用最新制度条款,帮助 HR、合规和业务团队减少重复咨询,并保持回答口径一致。
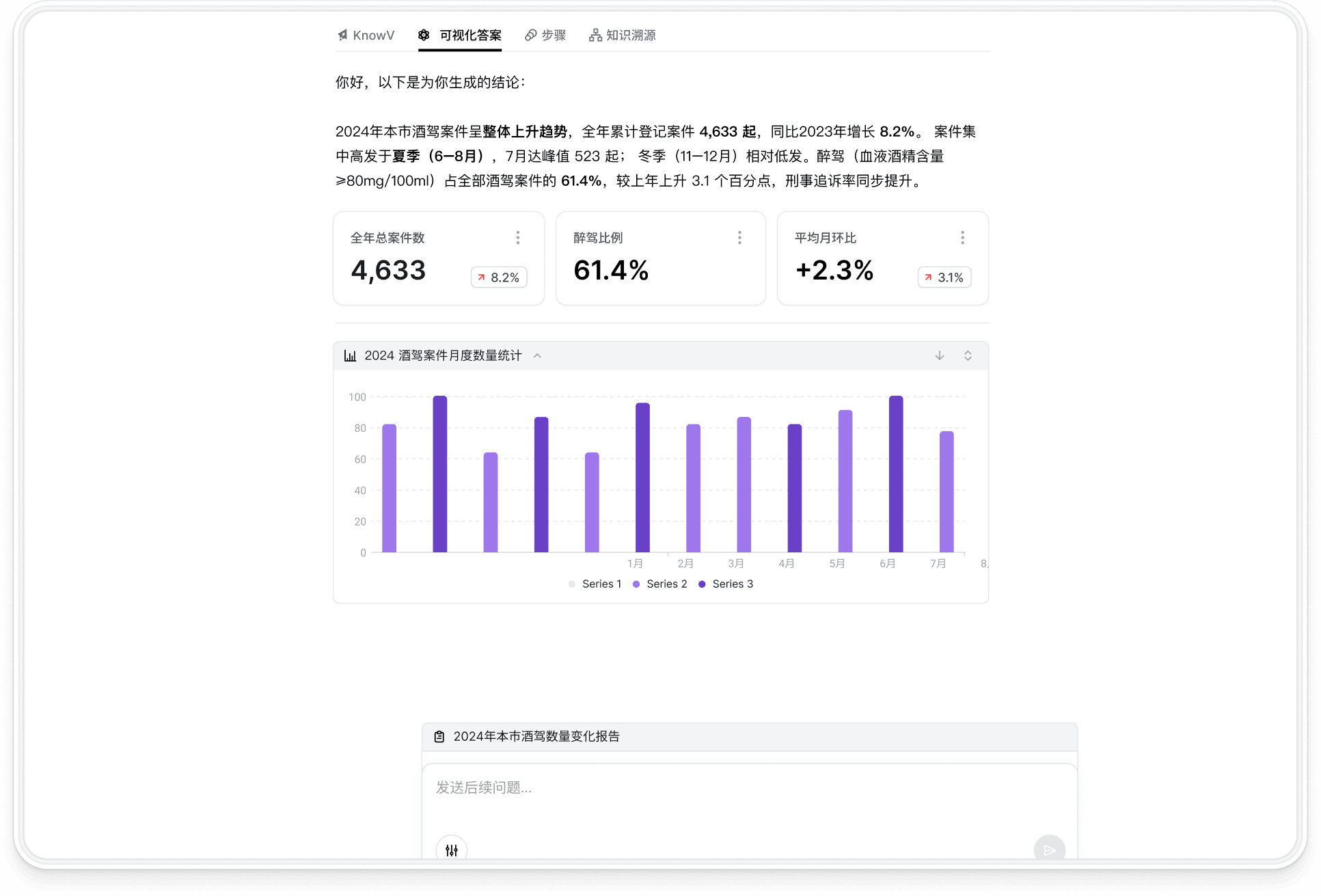
自动拉取项目资料、会议记录、业务数据和历史经验,生成可追溯的复盘报告,减少跨系统整理成本。
用自然语言检索违规片段,识别异常事件,并自动关联处理流程、责任人员和历史案例。
原生内置智能体执行引擎,并深度注入企业知识。让智能体在解答疑问时,无缝调用业务数据、执行自动化流程时,严格遵循企业规范。
从省级公安厅、地市公安局交管大队到工信部直属科研机构,KnowV 正在支撑高安全、高复杂度场景下的知识管理、视频分析与智能体执行。
挑战
海量警务文档与业务知识分散,跨警种、跨地市检索和复用成本高。
成果
建成全省统一、安全可控的智慧警务知识底座,支撑 20万+ 用户,实现 3万+ 核心业务文档的结构化管理与警情智能处置。
用户规模
20万+
业务文档
3万+
部署形态
安全可控全信创
适合希望快速构建知识体系、低成本验证 AI 场景价值、无需关注底层模型运维的创新团队与成长型企业。
内置业界领先大模型能力,无需关注底层算力与模型部署,开箱即用。
内置业界领先智能体平台,与企业知识无缝衔接,帮助企业快速构建业务流程、数据分析、运营协同等场景的智能体应用。
根据任务复杂度自动匹配最优模型,在保障推理效果的同时极致优化调用成本。
支持组织权限、知识访问控制与操作留痕,保障团队知识安全使用。
打破传统软件按人计费,按实际业务调用量灵活计费,降低企业 AI 试错门槛。
适合政务、金融、大型制造及国企等重视数据绝对安全、深度系统集成与长期知识资产建设的组织。
支持本地机房或专属云部署,确保企业核心数据不出域。
内置先进智能体平台,同时兼容企业现有智能体平台,通过统一知识底座连接知识、工具与业务系统,让知识真正参与业务执行。
提供细粒度的组织权限管控、完整审计日志与数据加密机制。
深度兼容主流信创生态(国产芯片、操作系统、数据库及主流国产大模型)。
提供标准 API 与定制开发服务,无缝对接企业现有业务系统。
KnowV 将企业知识从“资料集合”升级为可关联、可推理、可执行的知识体系。
文档、视频、业务数据、项目和人员自动关联,让一次查询获得完整业务背景。
围绕复杂问题进行多源交叉验证,输出可溯源的分析结果和决策依据。
把知识嵌入制度问答、项目复盘、视频巡检和内务协同,减少手工整理与反复查找。